计算机网络的基础知识:应用层
目录
应用层
学习《计算机网络——自顶向下方法》的总结,留以自用,打好基础
应用层协议原理
网络应用程序体系结构
主要有三类:
1.客户-服务器结构(Client-Server Architecture)
主要应用有:Web、FTP、Telnet、电子邮件等;
2.对等P2P结构(Peers-to-Peers Architecture)
文件共享(BitTorrent)、p2p下载加速器(迅雷)、网络电话(Skype)等;
3.混合(Client-Server + P2P)
即时通信应用——服务器跟踪用户IP地址,用户之间通过P2P直接发送接收报文(message)。
进程通信
网络中进行通信是实际是进程,不同主机的不同进程之间交换报文(message)来相互通信。
- 主机(host):可以被分配到IP地址的设备就可以认为是主机(host)或端系统(end system)
- 进程(process):可以认为程序是指令、数据及其组织形式的描述,进程是程序的实体
客户和服务器进程
一般情况下,我们可以认为发起通信的进程标识为客户(client),等待联系的进程是服务器(server)
例如:
- 浏览器 - Web服务器交换报文
- P2P 文件从一个对等方的进程传输到另一个counterpart的进程
进程与计算机网络之间的接口
- 套接字(Socket),是同一台主机内应用层与传输层之间的接口,是应用程序和网络之间的API
进程寻址
主机地址(IP地址)+ 接收进程标识符(端口号)
Internet提供的传输层协议
-
TCP服务——面向连接,全双工,可靠的数据传送服务,提供拥塞控制
-
UDP服务——无连接,不可靠数据传送服务
注意TCP和UDP都无加密机制,但TCP可以附加安全套接字层SSL加密,SSL实现在应用层。
Internet传输层协议不提供的服务 -
能为时间敏感应用提供满意的服务,但不提供任何定时(timing,感觉这个概念更接近于网络延时log)或带宽(throughput)保证
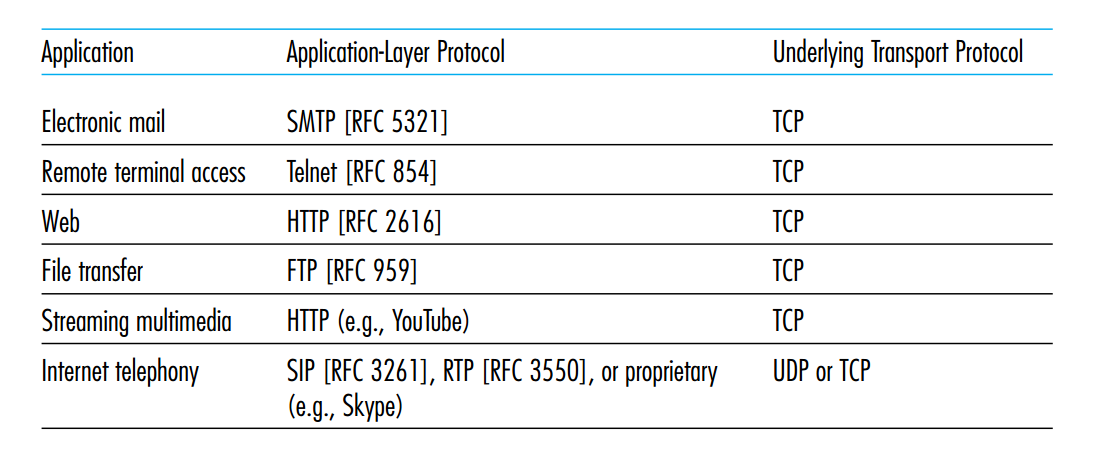
常见应用所需应用层协议
应用层协议定义
定义了运行在不同端系统上应用程序进程如何相互传递报文
- 报文类型,如请求报文,响应报文
- 报文类型的语法
- 报文的字段含义
- 何时、如何发送报文,响应规则
一些应用层具体应用
Web、FTP、电子邮件、DNS、BitTorrent、DHT
这些是应用层的一些具体应用
Web和HTTP
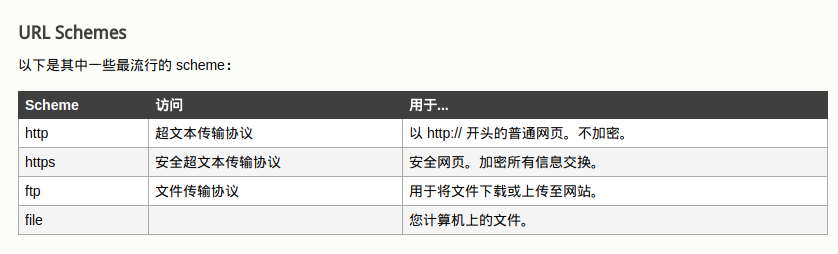
统一资源定位符(URL Uniform Resource Locator)
作为文件,网页需要有一个唯一的标识符来和其他网页区别开,为了定义一个网页,我们需要4个标识符:获取网页的协议、主机、端口、路径。
如下所示:
scheme://host.domain:port/path/filename
- scheme - 定义Internet服务的类型。最常见的类型是 http
- host - 定义域主机(http 的默认主机是 www)
- domain - 定义Internet域名,比如 w3school.com.cn
- :port - 定义主机上的端口号(http 的默认端口号是 80)
- path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
- filename - 定义文档/资源的名称
HTTP概况
- HTTP:The HyperText Transfer Protocol
- Web的应用层协议是超文本传输协议(HTTP),HTTP采用client-server结构,通过交换HTTP报文进行会话,使用80端口
- HTTP通过URL定位web服务器资源(网页、图片等)。URL地址包括主机名和路径名,Web服务器用于存储Web对象,每个对象由URL寻址
- HTTP使用TCP作为其支撑传输层协议
- HTTP是无状态协议(stateless protocol),即不保存client的信息
非持续连接和持续连接
- Non-persistent:每次的请求、响应在不同的TCP连接中
- persistent:每次的请求、响应在同一个TCP连接中
- Round-trip time(RTT)往返时间——packet-propagation delays + packet queuing delays + packet-processing delays
请求与接收一个HTML对象所需的时间,如下图所示。一个TCP连接时间:2个RTT+传输HTML文件的时间
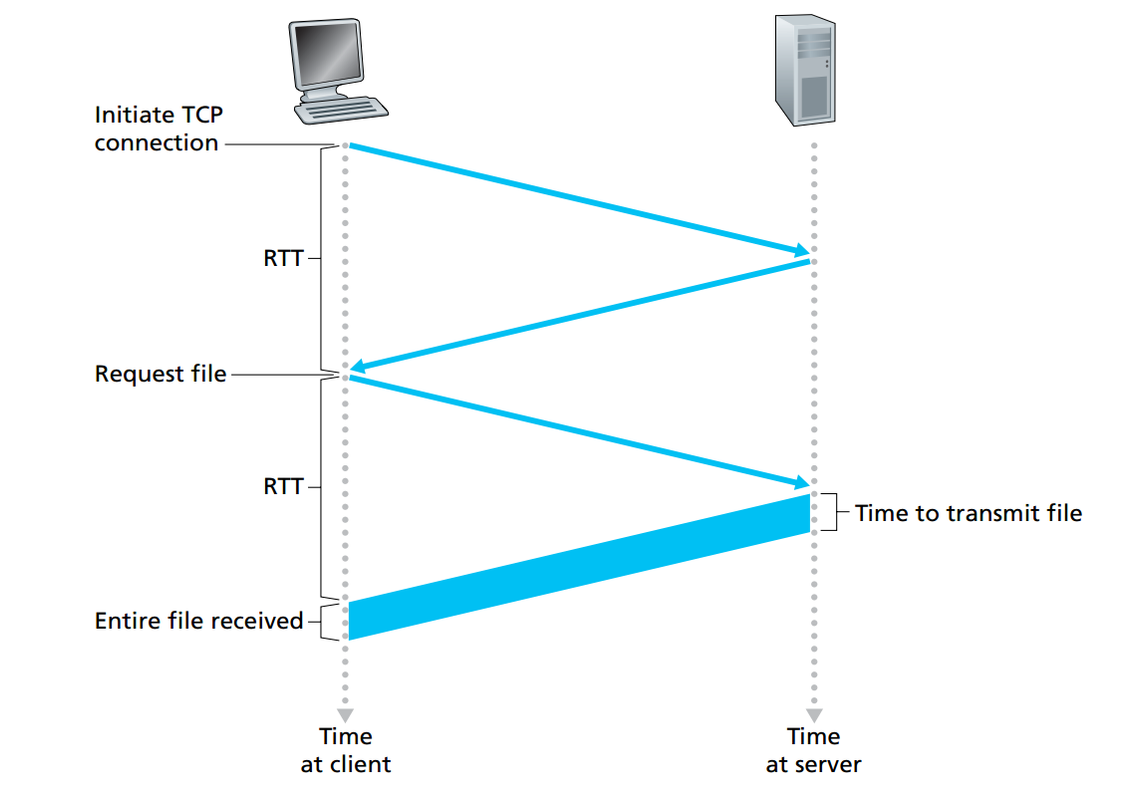
1.采用非持续连接的HTTP
- 每个TCP连接只传输一个请求报文和一个响应报文
- 每个连接在客户和服务器都要分配TCP的缓冲区和保持TCP变量
- TCP连接三次握手,第三次握手向TCP连接发送一个HTTP请求报文
- 缺点:
1.必须为每个请求建立和维护一个全新的连接,可能会给Web服务器带来严重的负担
2.每一个对象经受两倍RTT的交付时延,一个用于创建连接,一个用于请求和接收一个对象
2.采用持续连接的HTTP(default)
服务器发送响应后保持该TCP连接打开,经过一定时间间隔(超时)未被使用,HTTP服务器关闭该连接
HTTP报文格式
——(request message)请求报文
GET /somedir/page.html HTTP/1.1---------------------------------Request line
Host: www.someschool.edu-----------------------------------------Header line
Connection:close-------------------------------------------------Header line
User-agent: Mozilla/5.0------------------------------------------Header line
Accept-language: fr----------------------------------------------Header line
...
-
Request line请求行
-
method field——主要GET, POST, HEAD, PUT, DELETE
- GET 从指定的资源请求数据。
- POST 向指定的资源提交要被处理的数据,例如表单
- HEAD 与 GET 相同,但只返回HTTP报头,不返回文档主体。服务器会对请求HTTP报文产生响应,并不返回请求对象,用于调试跟踪
- PUT 用于client上传对象
- DELETE 删除web服务器上的对象
-
URL field
-
HTTP version field
-
Header lines首部行
-
Host: Web proxy caches需要(Web代理高速缓存使用)
-
Connection:close——浏览器告诉服务器使用No-persistent
-
User-agent:浏览器类型
-
Accept-language
-
cookies
-
…
-
Blank line空白行——\r\n
-
Entity body实体体——用于POST method
——(response message)响应报文
- 状态行(status line)
- 状态码(status code)200、301、400、404…详见此处
- 首部行(header line)
- blank line
- entity body
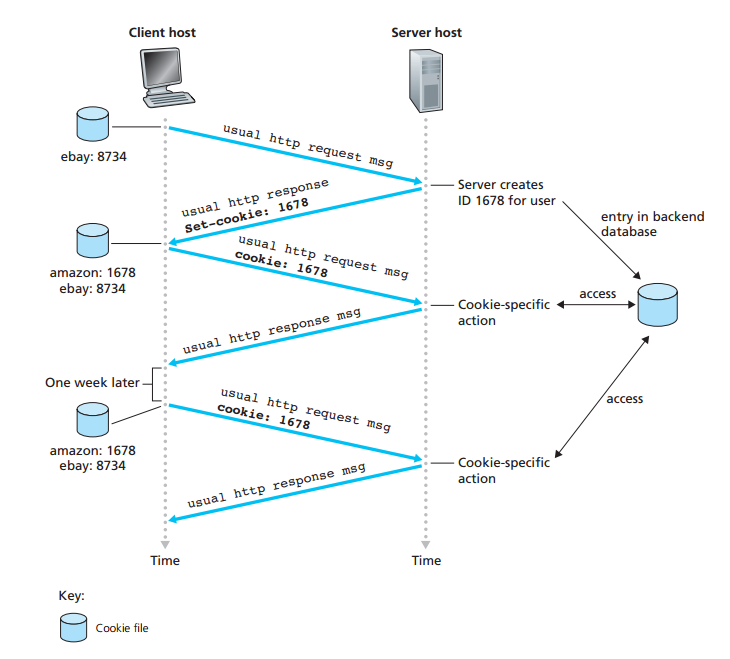
用户与服务器的交互:cookie
服务器希望限制用户访问,或希望把内容与用户身份联系起来
用户第一次请求服务器—>响应报文的响应头(首部行)带一个cookie—>浏览器管理cookie—>请求报文带cookie—>服务器根据cookie识别用户
Web缓存(proxy server代理服务器)
- web cache是可以代表初始web服务器来满足HTTP请求的网络实体
- web cache拥有自己的储存空间,并且将最近请求的对象保存在储存空间中
- web cache既可以是server也可以是client
- 可以显著的减少client的请求响应的时间
- 大大减少接入链路到Internet的网络流量,同时整体上减少Internet上的web流量
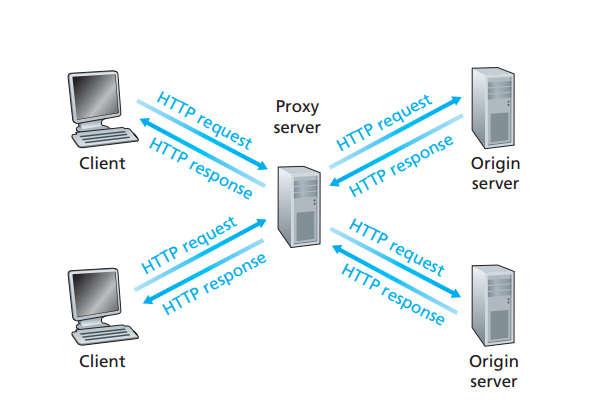
与CDN(内容分发网络)结合,使大量流量实现了本地化
条件Get方法
虽然web cache很有用,但会引入一个问题,储存在cache上的对象可能会过期,所以有了条件GET。
conditional GET:允许cache验证对象是否为最新的
web cache向server请求对象
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 7 Sep 2011 09:23:24
若server对象无更新,server响应web cache
HTTP/1.1 304 Not Modified
Date: Sat, 15 Oct 2011 15:39:29
Server: Apache/1.3.0 (Unix)
(empty entity body)
- 请求报文中包含“If-Modified-Since:” 位于header line
- 304 Not modified
文件传输协议FTP
- 基于TCP
- FTP使用两个并行TCP连接传输文件
- 控制连接(control connection):用于两主机之间传输控制信息,如:用户标识、口令、操作命令,贯穿整个用户会话期间,因此整个会话中,FTP服务器必须保存用户的状态信息
- 数据连接(data connection):传输文件,一个文件一个连接,非连续
- FTP的控制信息是带外传送的(如上),HTTP属于带内传送

电子邮件
STMP
- STMP:Simple Mail transfer Protocol
- 很古老。。。
- 需要将二进制多媒体数据编码为ASCII码,接收方再还原
- port 25
- persistent
- 不使用中间邮件服务器发送邮件,若接收方邮件服务器没开机,报文会保留在发送方邮件服务器上等待新的尝试
SMTP与HTTP对比
- HTTP是拉协议,SMTP是推协议
- HTTP把每个对象封装到自己的相应报文中,SMTP把所有报文放在一个报文中
邮件访问协议
- POP3:简单
- IMAP:有各种文件操作
- HTTP:基于Web的电子邮件
client的代理(qq邮箱客户端)—>SMTP/HTTP—>QQ邮箱服务器—>SMTP—>163邮箱服务器—>POP3/IMAP/HTTP—>client的代理(163邮箱Web端)
DNS:因特网的目录服务
- DNS:Domain Name System
- 一个由分层的DNS服务器实现的分布式数据库
- DNS也是一个允许主机查询这个分布式数据库的应用层协议
- DNS提供的服务:主机名—>IP地址转换的目录服务
- DNS(域名系统) = DNS服务器 + DNS协议
- DNS协议运行在UDP上,53号端口
- 通常由其他应用层协议使用,包括HTTP、SMTP、FTP
主机别名
邮件服务器别名,允许一个公司的邮件服务器和Web服务器使用相同主机名,可以利用主机别名来实现负载分配——一个站点若有多台服务器(多IP地址对应一个主机名),DNS服务器循环回答这些地址
DNS工作机理
分布式、层次数据库
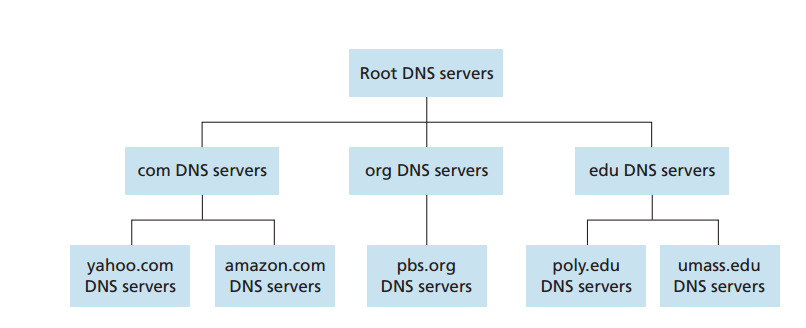
层次结构
- 根DNS服务器:13个根服务器(群),世界各地
- 顶级域(DNS)服务器:com/org/edu/uk/cn,由世界各公司维护
- 权威DNS服务器:自己维护,或存储在某服务提供商的一个权威服务器中
- 本地DNS服务器:当主机发出DNS请求时,先发往本地服务器,若无缓存,转发到DNS服务器层次结构中的根DNS服务器,迭代返回各层次DNS服务器地址,最后才能直接查询主机名对应的IP地址
递归查询、迭代查询,通常从请求主机到本地DNS服务器的查询是递归的,其余的查询是迭代的
DNS缓存
允许本地DNS绕过查询链中的根DNS服务器
有缓存时间
DNS记录和报文
- 资源记录(如果你在阿里的万网上注册一个域名,是需要这个配置的)
- A:主机名-IP地址,如(relay1.bar.foo.com, 145.37.93.126, A)
- NS:域名-DNS服务器主机名, 如(foo.com, dns.foo.com , NS)
- CNAME:别名-其他服务规范主机名,如( foo.com, relay1.bar.foo.com,
CNAME) - MX:别名-邮件服务器规范主机名(foo.com, mail.bar.foo.com, MX)
- DNS报文
- 查询报文
- 回答报文
在DNS数据库中插入记录
向某注册登录机构注册域名时(如万网),需要提供基本和辅助权威DNS服务器的名字和IP地址
安全性
- DDoS(分布式拒绝服务)带宽泛洪攻击:向处理如.com域的域名服务器发送大量DNS请求,使得大部分合法请求无法获得响应
- DNS毒害(污染):给你返回假的或不能用的IP地址。比如中国的『墙』。所以如果你能拿到google的当前IP地址(百度搜的到),手动在hosts里配置,是可以做到直接访问谷歌服务器的。说到翻墙,一般大家都是用某种方法配置一台海外服务器当做中转(国家一般不墙这种个人服务器),来访问墙外服务器的,比如shadowsocks,shadowrocket之类的软件可以用来配置中转服务器。
- DNS反射攻击:请求中冒充目标主机源地址,大量请求DNS服务器,DNS就大量向源地址主机发送回答,淹没目标主机
P2P应用
P2P文件分发(BitTorrent)
在P2P文件分发中,每个对等方能重新分发它所有的该文件的任何部分,可以协助服务器分发
P2P体系结构的扩展性
最小分发时间,对等方N越大,P2P的最小分发时间越小
对等方除了是比特的消费者外还是他们的重新分发者
BitTorrent
P2P文件共享协议,参与一个特定文件分发的所有对等方结合被称为一个洪流(torrent),在一个洪流的对等方彼此下载等长度的文件块,可以随时离开洪流,也可继续向其他对等方上载
- Alice加入某洪流时,会在追踪器里进行注册,周期性通知追踪器它仍在洪流中。
- 洪流随机从参与对等方的结合中选择一个子集,将他们的IP地址发给Alice,Alice维护这张对等方列表,视图与所有对等方建立并行的TCP连接。
- Alice周期询问每个邻近对等方(连上的)他们有的文件块列表,她随时知道邻居有哪些文件块
- Alice使用最稀缺优先技术,首先请求那些邻居们副本数量最少的块,使该文件块迅速分发,以均衡每个块在洪流中的副本数量
- BitTorrent使用一种算法,Alice优先从像她传时速度最快的邻居(4个,每10s修改一次)那里获取文件块。
- 每过30s,Alice也要随机选择另外一个对等方Bob,向他发送块。若Alice是Bob最快的前四快,Bob也是Alice的前4快,则Bob和Alice互相发送数据。
- 每过30s换一个新的对象,互相交换数据(一报还一报),为了使对等方能够找到彼此协调的速率上传
- BitTorrent其他机制和变种片、流水线、随机优先选择、残局模型、反怠慢等机制
- 变种:P2P直播流式应用,如PPLive和PPstream
分布式散列表(DHT)
- 分布式、P2P版本的key-value数据库,在大量对等方上存储key-value值(键值对)
- 分布式数据库用来定位拥有某key-value的对等方,然后向查询方返回该键值对
- 环形DHT、对等方扰动