定时事件与时间轮
目录
在程序中,有许多事件都是定时事件,如定期检测一个连接的活动状态、连接信息等。这些定时事件的数量庞大,因此如何有效的管理这些定时事件对于程序的性能相当重要。
常见的实现管理定时事件的方式有三类:
- 基于链表
- 基于最小堆(树)
- 基于时间轮
它们都依赖于周期性的tick来触发定时器(这里的定时器其实是定时事件管理器,好像一般都称之为定时器)操作,执行相应的定时事件;其中基于时间轮及其变体的实现方式效率比较好,被广泛应用于Netty、Kafka等程序中。
其实在George Varghese和Tony Lauck在1987年提出的论文中,就把这些方法都总结了一遍,并提出了著名的 Hierarchical Timing Wheel,本文图片来自于论文ppt。

来自于论文ppt
他们将计时器建模为由两个提供给外部调用的操作,用于设置和停止一个定时事件(接下来也称之为timer)
- Start Timer
START_TIMER(Interval, Request_ID, Expiry_Action) - Stop Timer
STOP_TIMER(Request_ID)
以及两个内部操作
- Per-tick Bookkeeping
PER_TICK_BOOKKEEPING用于每个计时器的tick到来时,需要做的操作 - Expiry Processing
EXPIRY_PROCESSING其实就是定时事件到期时需要做的操作,各种方法没啥区别,所有在分析时忽略即可。
接下来看下这些实现方式的基本原理。
基于链表
无序链表
- 使用链表维护定时事件,如下图左边所示
- Start Timer - 只需要将定时事件插入链表尾部,
O(1) - Stop Timer - 虽然Start Timer只返回了Request_ID,如果直接在链表里查找是
O(n)(n为定时事件个数) ,不过可以在Start Timer的时候直接返回相应的定时事件,因此停止是O(1) - Per-tick Bookkeeping - 每次tick到来,都需要遍历一遍链表,检查定时事件是否到期,如果到期执行相应操作;没有到期的话,如果定时事件储存的是绝对时间,则无需处理,若是相对时间则需要将定时事件的到期时间减去tick的时间间隔。
O(n)

来自于论文ppt
有序链表
- 使用有序的链表维护定时事件,需要定时事件存储绝对时间,如上图右边所示
- Start Timer - 因为有序,需要根据定时事件的到期时间对有序链表进行排序,
O(n) - Stop Timer -
O(1) - Per-tick Bookkeeping - 因为是有序的,每次tick到来,都只需要处理距离到期时间最近的定时事件,因此是
O(1) - 因为Per-tick Bookkeeping的操作更频繁,所有有序链表还是要比无需链表更好
基于最小堆(树)
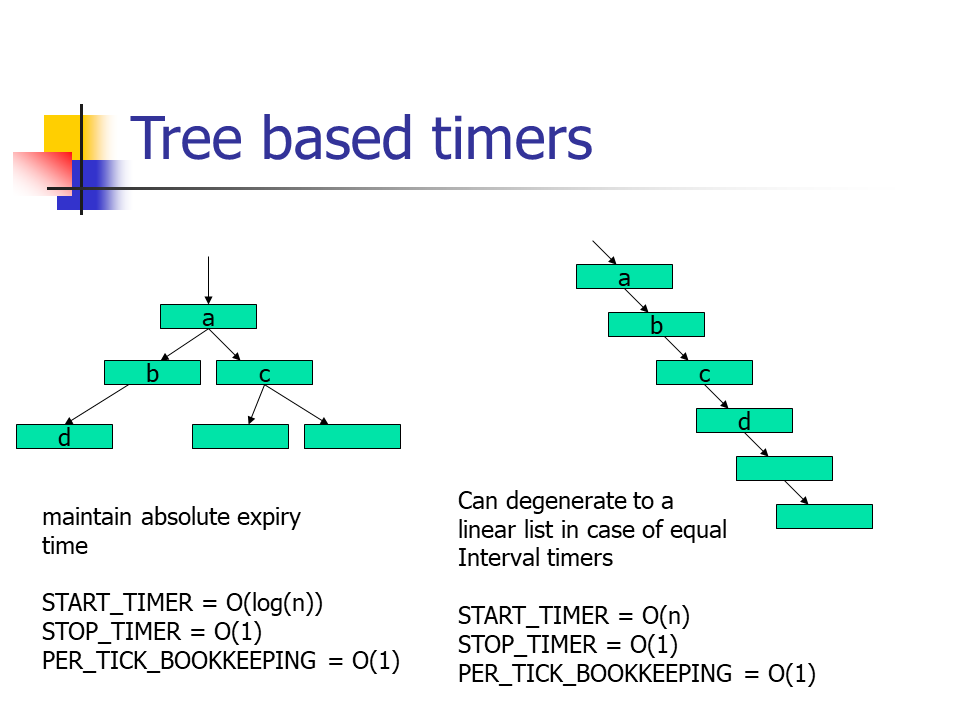
来自于论文ppt
- 其实还是有序链表的思想,只是用最小堆来维护定时事件
- Start Timer - 插入最小堆或树
O(lgn), 最坏情况下退化到O(n) - Stop Timer -
O(1) - Per-tick Bookkeeping - 因为是有序的,每次tick到来,都只需要处理距离到期时间最近的定时事件,因此是
O(1) - 相比于有序链表,优化了插入定时事件的效率
基于时间轮
简单时间轮
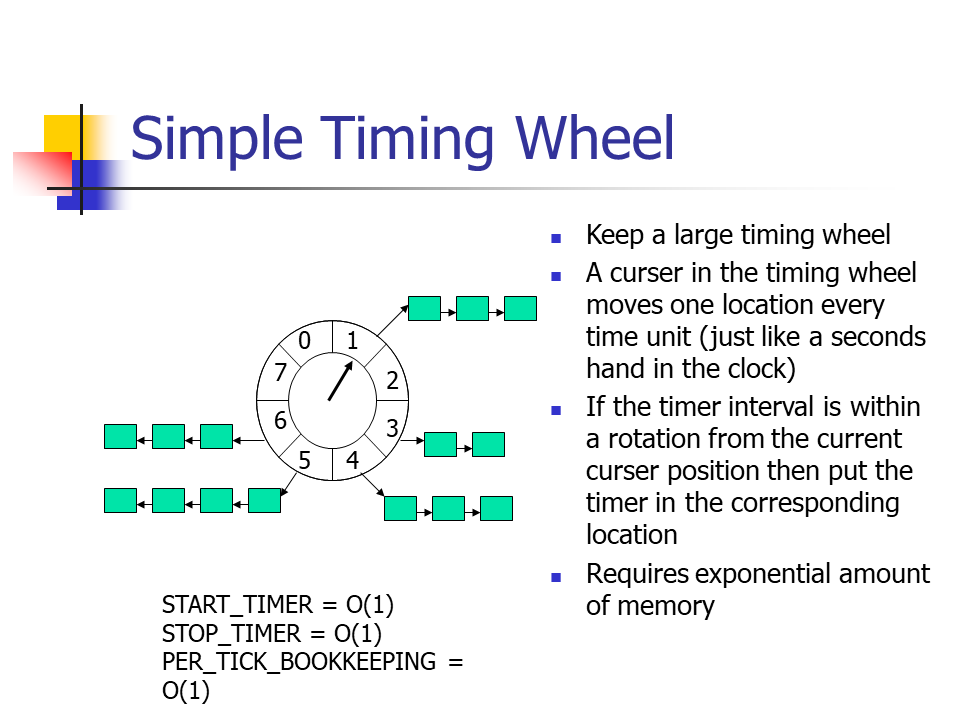
来自于论文ppt
- 使用一个ringbuffer来管理定时事件,ringbuffer的每个slot包含一个定时事件链表
- 指针指向当前slot,tick到来则指针指向下一个slot
- 可以很容易的计算出一个简单时间轮可以包含的定时事件的最大到期间隔为
N * t(N为ringbuffer的slot个数,t为tick的时间间隔) - Start Timer - 定时任务到期时间除以tick的时间间隔,即可可以计算出定时事件应放到哪个slot里,
O(1) - Stop Timer -
O(1) - Per-tick Bookkeeping - tick到来时,指针执行下个slot并执行相应的操作,
O(1) - 缺点
- 一旦选定了ringbuffer的slot个数和tick的时间间隔,则无法包含到期时间间隔大于
N * t的定时事件- 可以通过增加轮次信息来解决无法包含到期时间间隔大于
N * t的问题,但是这也会引入新的问题。之前每个slot里都是要执行的定时事件,增加轮次信息之后,需要对链表进行遍历,确定定时事件属于哪个轮次;如果是有序链表或最小堆,则需要在插入时做额外操作。对其的分析可以见下方的Hashed Wheel with Ordered Timer Lists OR Unordered Timer Lists
- 可以通过增加轮次信息来解决无法包含到期时间间隔大于
- 如果定时事件的到期时间跨度大但数量少,会导致存储效率非常低下
- 一旦选定了ringbuffer的slot个数和tick的时间间隔,则无法包含到期时间间隔大于
Hashed Wheel with Ordered Timer Lists OR Unordered Timer Lists
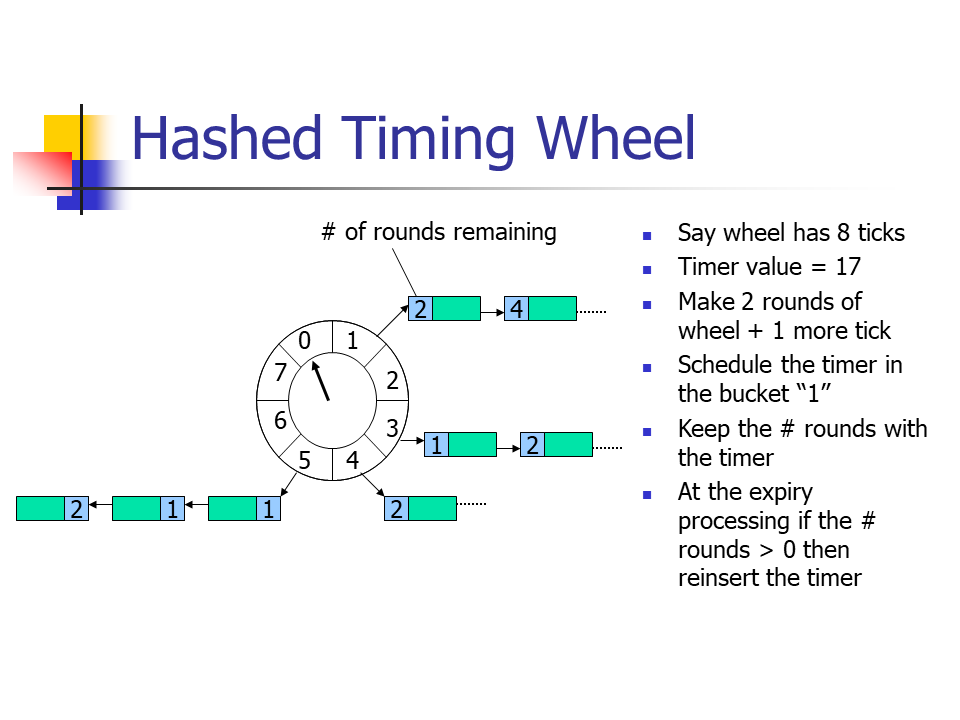
来自于论文ppt

来自于论文ppt
- 简单时间轮如果想要存储非常大的到期时间间隔的定时事件,并不是一个好的选择
- 如果使用hash将到期时间映射到ringbuffer的slot中,而不使用一个slot存储一个tick时间间隔这种方式,怎么样呢?
- 问题和增加轮次信息是一样的,需要对链表进行遍历,确定定时事件属于哪个轮次;如果是有序链表或最小堆,则需要在插入时做额外操作。
- Start Timer
- 有序链表,最坏情况
O(n),平均O(1) - 无序链表,
O(1)
- 有序链表,最坏情况
- Stop Timer -
O(1) - Per-tick Bookkeeping
- 有序链表,
O(1) - 无序链表,最坏
O(n),平均O(1)
- 有序链表,
接下来是对这个问题的另一种解决方案,层次时间轮(Hierarchical Timing Wheel )
层次时间轮 Hierarchical Timing Wheel
- 另一种处理由简单的时间轮引起的内存问题的方法是在层次结构中使用多个定时轮。假设我们需要一个秒级的定时器,并存储未来100天的定时事件,可以构建4个时间轮:
- 100个slot的天级时间轮
- 24个slot的小时级时间轮
- 60个slot的分钟级时间轮
- 60个slot的秒级时间轮
- 4个时间轮,244个slot,可以处理总共8.64 million个可能的计时器值。
- 每当在一个轮上完成一次完整的旋转,就把下一个时间粒度更大的轮推进一个slot。也就是说小的轮可以存储的全部到期时间间隔,就是下一个时间粒度更大的轮的一个slot。
- 然后,将下一个时间粒度更大的轮的事件插入到小的轮上,继续小的轮旋转。
- 此时类似于一系列新的定时事件插入一个简单时间轮,只不过这一系列新的定时事件来自于下个时间粒度更大的轮的一个slot。
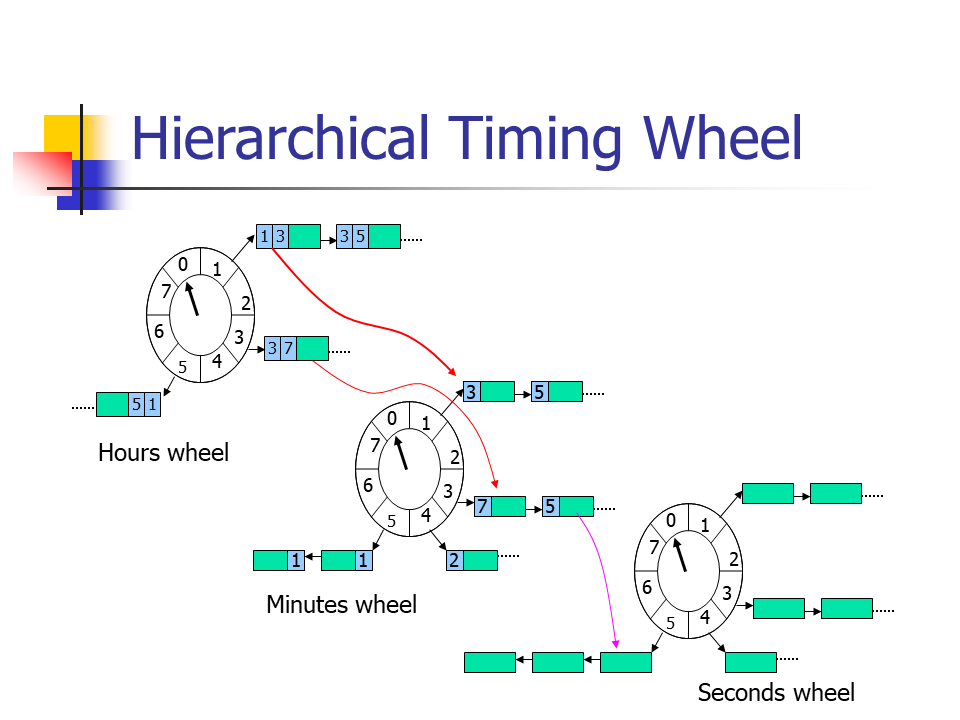
来自于论文ppt

来自于论文ppt
- Start Timer -
O(m),m为时间轮个数。 - Stop Timer -
O(1) - Per-tick Bookkeeping - tick到来时,指针执行下个slot并执行相应的操作,
O(1)
比较
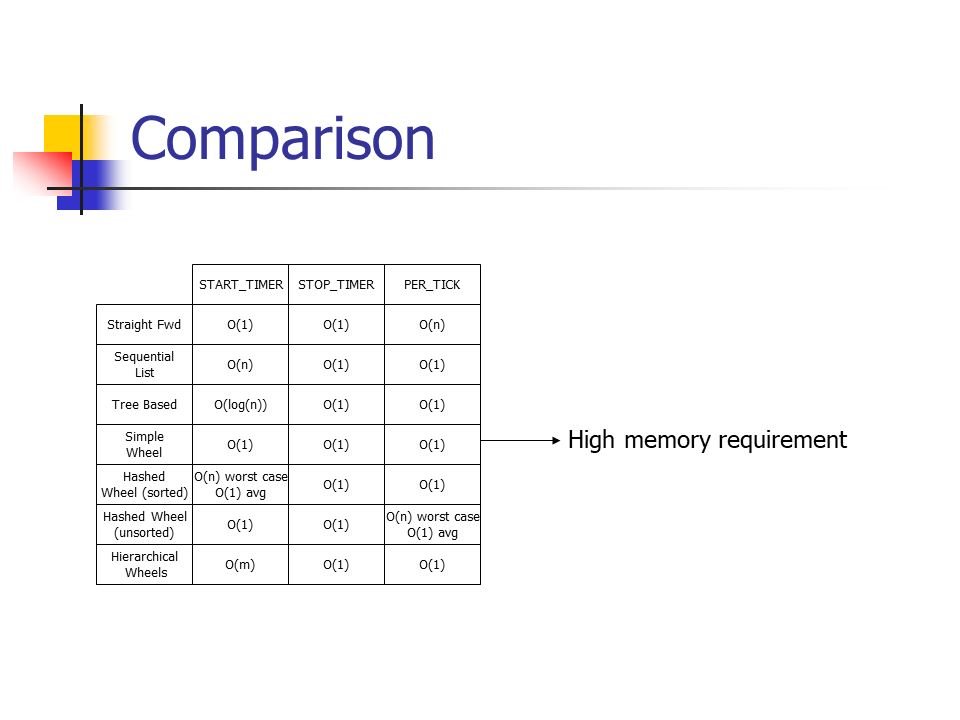
来自于论文ppt
更改时钟驱动方式
- 上面提及的方式都是基于tick来驱动时间轮,检查这一slot中是否包含定时任务。
- 如果时间单位 tick 很小(比如 Kafka 中 tick 为 1ms)并且(在最低层时间轮的)定时任务很少,那么这种驱动方式将会非常低效。
- 一种思路是将定时器中到期时间最小的一个timer的超时值作为tick的时间间隔。这样,一旦tick到来,到期时间最小的定时事件必然到期。然后再从剩余的定时事件中找出到期时间最小的一个,设置为tick的时间间隔。
- 对于层次时间轮,kafka的优化就是利用了这个思想
- 将每层时间轮中的有定时事件的slot加入DelayQueue中,等存在slot到期后驱动时间轮向前走。虽然 DelayQueue 中 offer(添加)和 poll(获取并删除)操作的时间复杂度为 O(log n),但是每层时间轮的slot数量是很少的,因此性能没有问题。