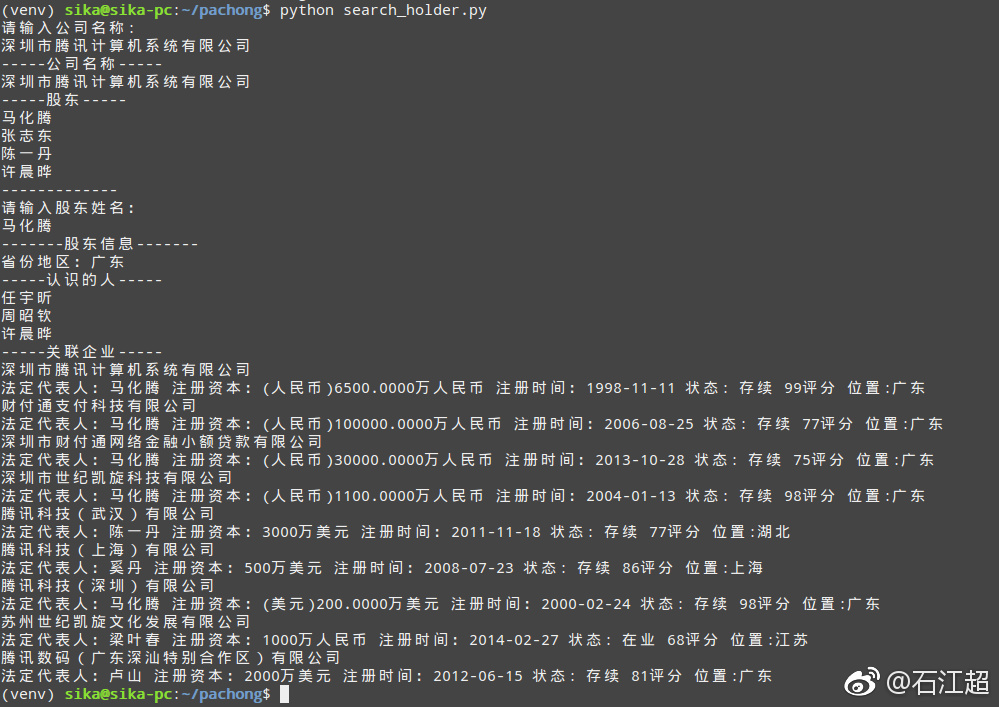
参考了这篇文章简单爬取天眼查数据(非严谨)
大四了,想找个实习,联系了几家公司,以前没编过爬虫,只了解了些概念,然后有一个公司让我编个爬虫试试看,就是用python实现从天眼查提取指定公司的所有股东,我想了想,编编看,然后完成了这个小东西。
分析天眼查网站,通过火狐抓包,发现必须要解析JavaScript才能拿到真实的数据,网上查找了下,发现使用phantomjs是比较简单的一种方式。
所以选择用selenium 和 phantomjs来获取页面源代码,用BeautifulSoup4 + lxml来解析页面内容,用的python2.7
使用selenium+PHANTOMJS获取源代码,
selenium简单教程-----Python爬虫利器五之Selenium的用法
phantomjs简单教程-----Python爬虫利器四之PhantomJS的用法
为phantomjs添加useragent信息
1
2
3
4
5
6
7
| def driver_open():
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"
)
driver = webdriver.PhantomJS(desired_capabilities=dcap)
return driver
|
获取网页源代码
1
2
3
4
5
6
7
8
| def get_content(driver,url):
driver.get(url)
time.sleep(2)
content = driver.page_source.encode('utf-8')
soup = BeautifulSoup(content, 'lxml')
return soup
|
可以通过 print content 来简单验证页面内容爬的对不对
使用BeautifulSoup4 + lxml来解析页面内容
BeautifulSoup4教程-----Beautiful Soup 4.2.0 文档
接下去解析代码,获取对应的信息。
查找指定公司页面url
先看天眼查搜索格式
'http://www.tianyancha.com/search?key=' + key + '&checkFrom=searchBox'
然后用BeautifulSoup4解析网页源代码
通过urllib.qutoe()方法,以防传入的keyname出现错误编码
1
2
3
4
5
6
7
8
| def search_url(keyname):
key = urllib.quote(keyname)
search_url = 'http://www.tianyancha.com/search?key=' + key + '&checkFrom=searchBox'
res_soup = get_content(driver, search_url)
ifname = res_soup.find_all(attrs={"ng-bind-html": "node.name | trustHtml"})
name = ifname[0].text
ifcompany = res_soup.find_all(attrs={"ng-click": "$event.preventDefault();goToCompany(node.id);inClick=true;"})
return ifcompany[0].get('href')
|
查找股东页面url
有了公司页面url,通过phantomjs来获取公司页面源代码,然后解析内容,获得指定公司的基本信息和所有股东信息
然后输入股东格名,获得股东页面url。
在输入股东姓名时,需要注意python2的编码问题,从网页获得的股东姓名格式是unicode,而在Bash里输入的股东姓名是以string的形式,所以在这里需要对输入的股东姓名重新编码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def get_company_info(company_url):
soup = get_content(driver, company_url)
company = soup.select('div.company_info_text > div.ng-binding')[0].get_text()
print "-----公司名称-----"
print company
tzfs = soup.find_all(attrs={"event-name": "company-detail-investment"})
print "-----股东-----"
for i in range(len(tzfs)):
tzf_split = tzfs[i].text.replace("\n","").split()
tzf = ' '.join(tzf_split)
print tzf
print "-------------"
holder_name = raw_input('请输入股东姓名:\n').decode('utf-8')
for i in range(len(tzfs)):
if [holder_name] == tzfs[i].text.split():
break
holder_url = soup.find_all(attrs={"event-name": "company-detail-investment"})
return 'www.tianyancha.com' + holder_url[i].get('href')
|
获得股东信息
接下来就获取到了股东信息,就结束了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| def get_holder_info(human_url):
human_soup = get_content(driver, "http://"+human_url)
print "-------股东信息-------"
base_info = human_soup.find_all(attrs={"ng-if": "singleHumanBase"})
print base_info[0].text
print "-----认识的人-----"
rpersons = human_soup.find_all(attrs={"ng-if" : "relatedHuman.name"})
for i in range(len(rpersons)):
rperson_split =rpersons[i].text.replace("\n","").split()
rperson = ' '.join(rperson_split)
print rperson
print "-----关联企业-----"
rcompanys = human_soup.find_all(attrs={"ng-bind-html": "node.name | trustHtml"})
some_info = human_soup.select('div.title')
state_infos = human_soup.find_all(attrs={"ng-class": "initStatusColor(node.regStatus);"})
rate_infos = human_soup.select('svg')
base_infos = human_soup.select('div.search_base ')
for i in range(1, len(rcompanys)+1):
state_info_split = state_infos[i-1].text.replace("\n","").split()
state_info = ' '.join(state_info_split)
rcompany_split =rcompanys[i-1].text.replace("\n","").split()
rcompany = ' '.join(rcompany_split)
rate_info = rate_infos[i-1].text
rate_u = "评分".decode('utf-8')
base_info_split = base_infos[i-1].text.replace(rate_u,"").split()
base_info = ' '.join(base_info_split)
some_info_1 = some_info[3*i - 3].text.replace(" ","")
some_info_2 = some_info[3*i - 2].text.replace(" ","")
some_info_3 = some_info[3*i - 1].text.replace(" ","")
print rcompany + '\n'+ some_info_1 + ' '+ some_info_2 + ' '+ some_info_3 + u' 状态: ' + state_info + ' ' + rate_info + u' 位置:' + base_info[0:2]
|
整合------全部代码:
总的来说,这仅仅是单页面的一个示例,而且还有很多地方语句写的不优美,以后再花时间改进。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
from selenium import webdriver
import time, urllib
from bs4 import BeautifulSoup
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def driver_open():
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"
)
driver = webdriver.PhantomJS(desired_capabilities=dcap)
return driver
def get_content(driver,url):
driver.get(url)
time.sleep(2)
content = driver.page_source.encode('utf-8')
soup = BeautifulSoup(content, 'lxml')
return soup
def search_url(keyname):
key = urllib.quote(keyname)
search_url = 'http://www.tianyancha.com/search?key=' + key + '&checkFrom=searchBox'
res_soup = get_content(driver, search_url)
ifname = res_soup.find_all(attrs={"ng-bind-html": "node.name | trustHtml"})
name = ifname[0].text
ifcompany = res_soup.find_all(attrs={"ng-click": "$event.preventDefault();goToCompany(node.id);inClick=true;"})
return ifcompany[0].get('href')
def get_company_info(company_url):
soup = get_content(driver, company_url)
company = soup.select('div.company_info_text > div.ng-binding')[0].get_text()
print "-----公司名称-----"
print company
tzfs = soup.find_all(attrs={"event-name": "company-detail-investment"})
print "-----股东-----"
for i in range(len(tzfs)):
tzf_split = tzfs[i].text.replace("\n","").split()
tzf = ' '.join(tzf_split)
print tzf
print "-------------"
holder_name = raw_input('请输入股东姓名:\n').decode('utf-8')
for i in range(len(tzfs)):
if [holder_name] == tzfs[i].text.split():
break
holder_url = soup.find_all(attrs={"event-name": "company-detail-investment"})
return 'www.tianyancha.com' + holder_url[i].get('href')
def get_holder_info(human_url):
human_soup = get_content(driver, "http://"+human_url)
print "-------股东信息-------"
base_info = human_soup.find_all(attrs={"ng-if": "singleHumanBase"})
print base_info[0].text
print "-----认识的人-----"
rpersons = human_soup.find_all(attrs={"ng-if" : "relatedHuman.name"})
for i in range(len(rpersons)):
rperson_split =rpersons[i].text.replace("\n","").split()
rperson = ' '.join(rperson_split)
print rperson
print "-----关联企业-----"
rcompanys = human_soup.find_all(attrs={"ng-bind-html": "node.name | trustHtml"})
some_info = human_soup.select('div.title')
state_infos = human_soup.find_all(attrs={"ng-class": "initStatusColor(node.regStatus);"})
rate_infos = human_soup.select('svg')
base_infos = human_soup.select('div.search_base ')
for i in range(1, len(rcompanys)+1):
state_info_split = state_infos[i-1].text.replace("\n","").split()
state_info = ' '.join(state_info_split)
rcompany_split =rcompanys[i-1].text.replace("\n","").split()
rcompany = ' '.join(rcompany_split)
rate_info = rate_infos[i-1].text
rate_u = "评分".decode('utf-8')
base_info_split = base_infos[i-1].text.replace(rate_u,"").split()
base_info = ' '.join(base_info_split)
some_info_1 = some_info[3*i - 3].text.replace(" ","")
some_info_2 = some_info[3*i - 2].text.replace(" ","")
some_info_3 = some_info[3*i - 1].text.replace(" ","")
print rcompany + '\n'+ some_info_1 + ' '+ some_info_2 + ' '+ some_info_3 + u' 状态: ' + state_info + ' ' + rate_info + u' 位置:' + base_info[0:2]
if __name__=='__main__':
try:
driver = driver_open()
except Exception, e:
print e
company_name=raw_input("请输入公司名称:\n")
company_url = search_url(company_name)
human_url = get_company_info(company_url)
get_holder_info(human_url)
driver.close()
|
这里以腾讯为例: