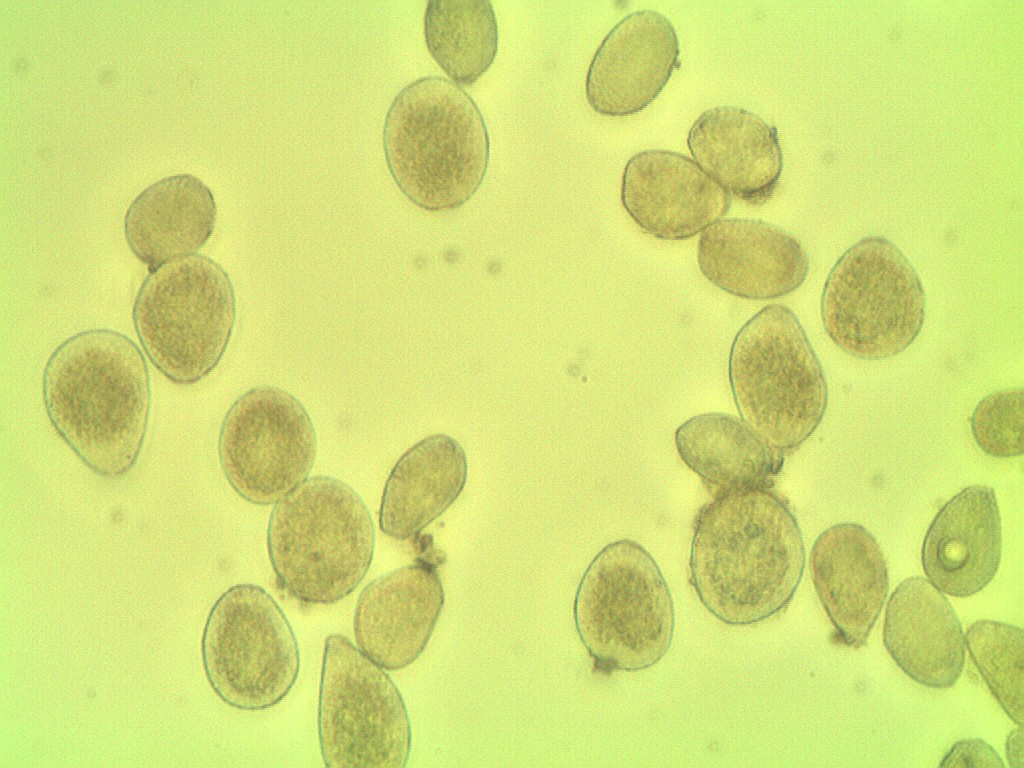
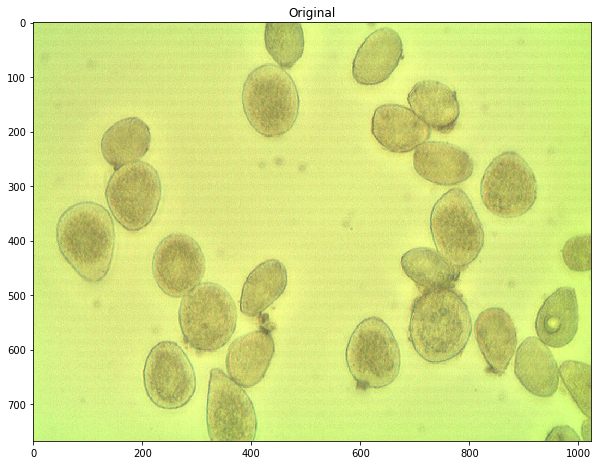
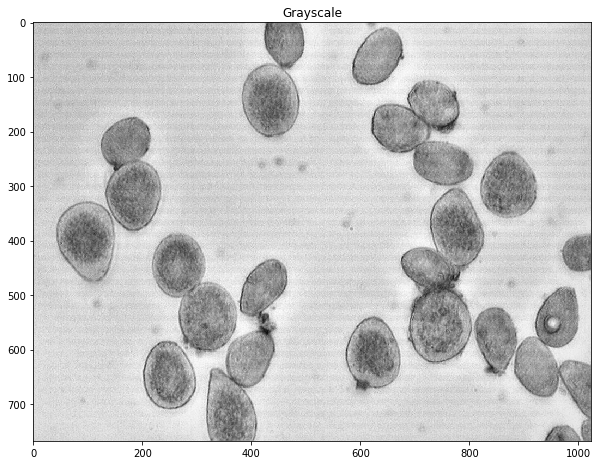
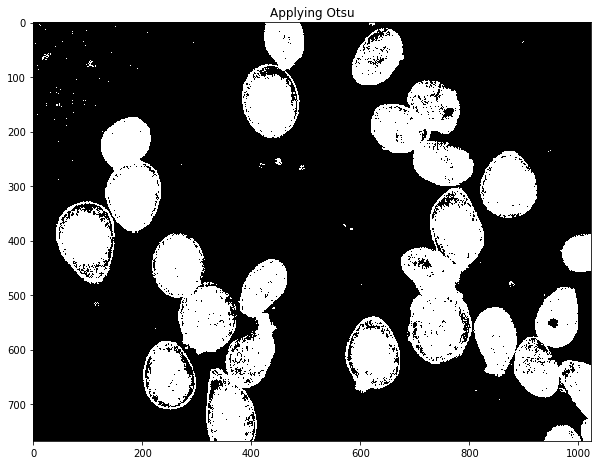
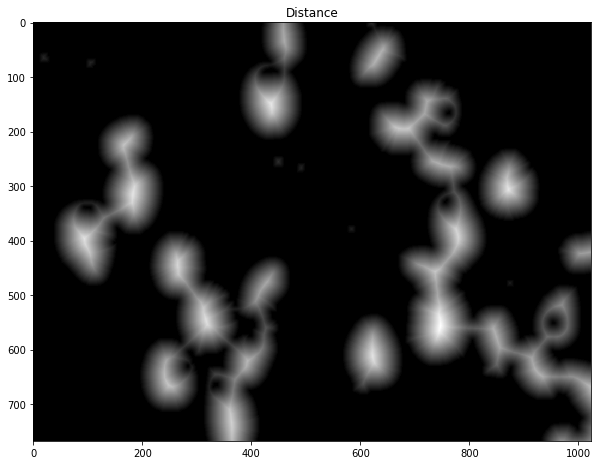
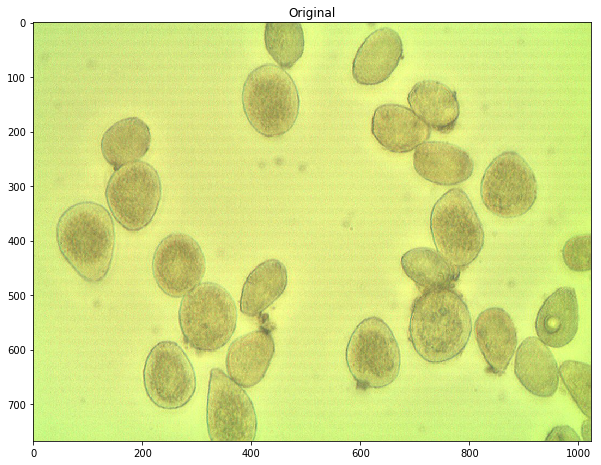
defCountCells(dilation=5, fg_frac=0.6): #Read in image img = cv2.imread('cell.jpg') #Convert to a single, grayscale channel gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #Threshold the image to binary using Otsu's method ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) #Adjust iterations until desired result is achieved kernel = np.ones((3,3),np.uint8) dilated = cv2.dilate(thresh, kernel, iterations=dilation) #Calculate distance transformation dist = cv2.distanceTransform(dilated,cv2.DIST_L2,5) #Adjust this parameter until desired separation occurs fraction_foreground = fg_frac ret, sure_fg = cv2.threshold(dist,fraction_foreground*dist.max(),255,0) # Finding unknown region unknown = cv2.subtract(dilated,sure_fg.astype(np.uint8)) # Marker labelling ret, markers = cv2.connectedComponents(sure_fg.astype(np.uint8)) # Add one to all labels so that sure background is not 0, but 1 markers = markers+1 # Now, mark the region of unknown with zero markers[unknown==np.max(unknown)] = 0 markers = skwater(-dist,markers,watershed_line=True) return len(set(markers.flatten()))-1
#Smaller numbers are noisier, which leads to many small blobs that get #thresholded out (undercounting); larger numbers result in possibly fewer blobs, #which can also cause undercounting. dilations = [4,5,6] #Small numbers equal less separation, so undercounting; larger numbers equal #more separation or drop-outs. This can lead to over-counting initially, but #rapidly to under-counting. fracs = [0.5, 0.6, 0.7, 0.8]
for params in itertools.product(dilations,fracs): print("Dilation={0}, FG frac={1}, Count={2}".format(*params,CountCells(*params)))