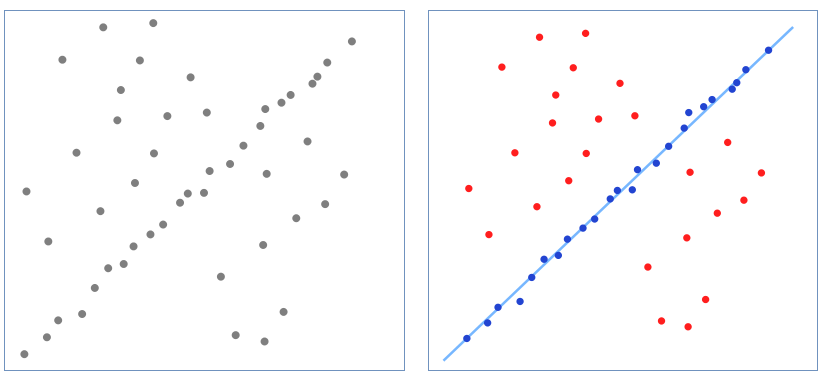
Given:
data - a set of observed data points
model - a model that can be fitted to data points
n - the minimum number of data values required to fit the model
k - the maximum number of iterations allowed in the algorithm
t - a threshold value for determining when a data point fits a model
d - the number of close data values required to assert that a model fits well to data
Return:
bestfit - model parameters which best fit the data (or nil if no good model is found)
RUN
iterations = 0
bestfit = nil
besterr = something really large
while iterations < k
maybeinliers = n randomly selected values from data
maybemodel = model parameters fitted to maybeinliers
alsoinliers = empty set
for every point in data not in maybeinliers
if point fits maybemodel with an error smaller than t
add point to alsoinliers
if the number of elements in alsoinliers is > d
% this implies that we may have found a good model
% now test how good it is
bettermodel = model parameters fitted to all points in maybeinliers and alsoinliers
thiserr = a measure of how well model fits these points
if thiserr < besterr
bestfit = bettermodel
besterr = thiserr
increment iterations
return bestfit
classLineModel(Model): """ A 2D line model. """ def__init__(self): self.params = None self.dists = None deffit(self, data): """ Fits the model to the data, minimizing the sum of absolute errors. """ X = data[:,0] Y = data[:,1] A = np.vstack([X, np.ones(len(X))]).T k, m = np.linalg.lstsq(A, Y, None)[0] self.params = [k, m] self.residual = sum(abs(k * X + m - Y)) defdistance(self, samples): """ Calculates the vertical distances from the samples to the model. """ X = samples[:,0] Y = samples[:,1] k = self.params[0] m = self.params[1] dists = abs(k * X + m - Y) return dists
defransac(data, model, min_samples, min_inliers, iterations=100, eps=1e-10, random_seed=42): """ Fits a model to observed data. Uses the RANSC iterative method of fitting a model to observed data. """ random.seed(random_seed) if len(data) <= min_samples: raise ValueError("Not enough input data to fit the model.") if0 < min_inliers and min_inliers < 1: min_inliers = int(min_inliers * len(data)) best_params = None best_inliers = None best_residual = np.inf best_iteration = None for i in range(iterations): indices = list(range(len(data))) random.shuffle(indices) inliers = np.asarray([data[i] for i in indices[:min_samples]]) shuffled_data = np.asarray([data[i] for i in indices[min_samples:]]) try: model.fit(inliers) dists = model.distance(shuffled_data) more_inliers = shuffled_data[np.where(dists <= eps)[0]] inliers = np.concatenate((inliers, more_inliers)) if len(inliers) >= min_inliers: model.fit(inliers) if model.residual < best_residual: best_params = model.params best_inliers = inliers best_residual = model.residual best_iteration = i except ValueError as e: print(e) if best_params isNone: raise ValueError("RANSAC failed to find a sufficiently good fit for the data.") else: return (best_params, best_inliers, best_residual, best_iteration)
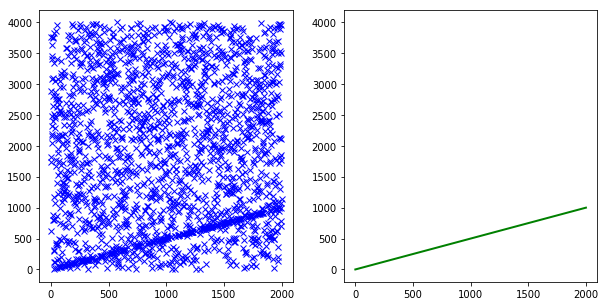
defsetup(): global ax1 X = np.asarray(range(num_samples)) Y = 0.5 * X noise = [random.randint(0, 2 * (num_samples - 1)) for i in range(num_noise)] Y[random.sample(range(len(Y)), num_noise)] = noise data = np.asarray([X, Y]).T model = Ransac.LineModel() plt.figure(figsize=(10,5)) ax1 = plt.subplot(1,2,1) plt.plot(X, Y, 'bx') return data, model
defrun(data, model): random_seed = random.randint(0,100) start_time = time.time() (params, inliers, residual, iterations) = Ransac.ransac(data, model, 2, (1 - noise_ratio) * num_samples, num_iterations, eps=0.1, random_seed=random_seed) end_time = time.time() mean_time = (end_time - start_time) / num_iterations return params, residual, mean_time, iterations defsummary(params, residual, mean_time, iterations): print(" Paramters ".center(40, '=')) print(params) print(" Residual ".center(40, '=')) print(residual) print(" Iteration ".center(40, '=')) print(iterations, "iteration finds the best params") print(" Time ".center(40, '=')) print("%.1f msecs mean time spent per iteration" % (1000 * mean_time)) X = np.asanyarray([0, num_samples - 1]) Y = params[0] * X + params[1] plt.subplot(1,2,2, sharey = ax1) plt.plot(X, Y, 'g-', linewidth=2) plt.show()
============== Paramters ===============
[0.5, -2.9994712862791754e-15]
=============== Residual ===============
1.0658141036401503e-14
============== Iteration ===============
404 iteration finds the best params
================= Time =================
3.3 msecs mean time spent per iteration